
Interactive TCP (iTCP) and Modified-TCP protocols
email: mailto:rzaghal@cs.kent.edu, homepage: http://www.mcs.kent.edu/~rzaghal
Prepared for Prof. Javed I. Khan
Department of Computer Science, Kent State University
Date: November 2001
Back to Javed I. Khan's Home Page
Table of Contents:
Introduction
TCP Performance Issues
Poor
use of the Network for short-lived connections
Interactive TCP
Other Approaches to Improve TCP Performance
Summary
References
Introduction:
The basic idea of TCP’s congestion control algorithm is to probe the available bandwidth of the network path that a TCP connection takes, and to adjust the sender’s congestion window to match the available path bandwidth. Network congestion sign shows up in the form of a duplicate ACK or a re-transmission timer out. The current implementation of TCP congestion control includes the classic algorithms of Slow-Start and Congestion Avoidance, and the augmentation of Fast-Retransmit and Fast Recovery algorithms.In this survey, we will first address some performance issues related
to TCP’s congestion control algorithms. Then,
we will present an interactive TCP mechanism (iTCP). This mechanism improves
data transport efficiency by sharing connection bandwidth information and
congestion control information with the application layer. This information
can be used by the application to adjust its transmission rate and fine-tune
according to the TCP situation.We
will also present two approaches suggested by researchers in this field
to deal with different kinds of congestion problems in TCP. Each approach
came up with a modified version of TCP’s congestion control mechanism to
improve TCP’s performance for certain applications. We will discuss the
basic idea of each improvement and try to evaluate its applicability and
its limitations. Then, we will compare between those approaches in terms
of the type of application or media that they can support.
TCP Performance Issues:
Support for heterogeneous
packet flows
In a multimedia stream, some parts of the packet flow will be more important
than others (e.g. audio over video, I-frames over B-frames in an MPEG stream,
text over images in Web pages), and should be transmitted with a higher
priority during network congestion. Also, flows may be composed of multiple
interleaved sub-streams, each of which has differing requirements in terms
of reliability, sequencing, and timeliness. Current TCP does not support
such heterogeneous packet flows.
Bursty packet
transmission
The window-based flow mechanism induces bursty packet transmissions, which
can make IP routers more susceptible to multiple packet losses. Depending
on the number of lost packets and the loss pattern, the performance of
a TCP connection can degrade significantly.
Poor use of the
Network for short-lived connections
The TCP slow-start algorithm often makes poor use of the network at connection
start-up time, when the network capacity is not the bottleneck. TCP slow-start
can require many round-trip times before achieving a steady state.
The slow-start algorithm works well for long-lived connections, but may
perform poorly with short-lived Web document transfers. Since most Web
documents are small (e.g., 4-20 kilobytes), a steady state may not
even be reached before a Web TCP connection terminates. As a result,
the round-trip times dominate the user-perceived response time.
Interactive TCP
Conceptual Overview
In the normal TCP scenario, the application opens a socket connection to
use TCP services. Once a TCP connection is established successfully, the
application uses this connection to transmit a byte stream to the TCP.
It is up to the TCP to take care of any congestion problems that might
rise up during transmission. The application is completely passive as far
as congestion control is concerned. The idea behind iTCP, is to get the
application involved when congestion arises. The iTCP will continuously
inform the application of any congestion events as they happen, and also
about the effective bandwidth currently available for iTCP to transmit
new segments. We believe this information is valuable to the application;
if the application knows that the TCP connection is suffering from congestion
problems and it has temporarily limited bandwidth, it will switch to a
slower rate, delivering less bytes to the TCP and consequently helping
the iTCP to overcome any congestion more effectively. When the congestion
is over and the more bandwidth opens for the iTCP, it will also notify
the application, which will in turn switch back to the normal rate.
State Diagrams
While studying congestion control algorithms mentioned above, we identified
a set of events that occur when the TCP runs congestion control algorithms.
In this section we present a simplified version of the Slow Start, and
the Fast Retransmit algorithms. For each algorithm we identify a set of
states and a set of events that triggers a transition from one state to
another. We present this information below as state diagrams.
i)
Slow Start
Slow start and Congestion
Avoidance are two independent algorithms but they are implemented together.
Slow start objective is to inject packets into the network at the same
rate at which packets are acknowledged. Congestion avoidance objective
is to slow down the transmission rate into the network when congestion
occurs. In the algorithm we maintain two variables: cwnd
(congestion window size) and ssthresh
(slow start threshold). The Slow Start and Congestion Avoidance combined
algorithm and state diagram are shown in figure 1 below. The set of events
and states shown in the state diagram are described in table 1 and Table
2 below.
initially,
cwnd = 1 (one segment);
ssthresh
= 65535 bytes.
win_size
= min (cwnd, snd_wnd);
When
congestion occurs:
ssthresh
= max((win_size)/2, 2);
if
congestion was due to timeout
cwnd
= 1/* perform slow start */
For
every ACK received:
if
(cwnd <= ssthresh)
cwnd
=2 * cwnd;/*
exponential increment */
else
cwnd
= cwnd + segment_size; /* linear increase */
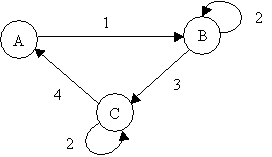
Figure
1. Slow Start algorithm and state diagram.
|
State
|
Meaning
|
Effective
transmission rate
|
|
A
|
Normal
state
|
Normal,
as specified by advertised window size and the last ACK received.
|
|
B
|
Linear
increment of cwnd
|
Starts
by one segment and increases exponentially with each ACK received.
|
|
C
|
Exponential
increment of cwnd
|
Starts
by ssthresh
value and increases by one with each ACK received.
|
Table
1. States during Slow Start.
|
Event
|
Meaning
|
Description
|
|
1
|
Retransmission
timer timed out.
|
Possibly
congested network or the segment was lost.
|
|
2
|
A
new ACK was received.
|
Increment snd_cwnd
either exponentially (if in state B) or linearly (if in state C).
|
|
3
|
snd_cwnd
has reached ssthresh.
|
Change snd_cwnd
incrimination from exponential to linear.
|
|
4
|
snd_cwnd
has reached the advertised window size snd_wnd.
|
Use
advertised window snd_wnd
instead of congestion window snd_cwnd.
|
Table
2. Events during Slow Start.
ii)
Fast Retransmit
In TCP if we receives
three or more duplicate ACKs, this means that a segment was lost. We need
to retransmit the lost segment before the retransmit timer expires.
After retransmitting the lost segment, we perform congestion avoidance
(called fast recovery). We don't need to perform slow start, since every
duplicate ACK received after retransmission means a packet has left the
network and we increase cwnd by one segment to keep cwnd packets in the
network. The Fast Retransmit algorithm and state diagram are shown in figure
2 below. The set of events and states shown in the state diagram are described
in table 3 and Table 4 below.
When
a 3rd duplicate ACK is received:
ssthresh
= (min(cwnd,snd_wnd))/2;
Retransmit
missing segment;
cwnd
= ssthresh + 3;
Each
time another duplicate ACK arrived, do:
cwnd
= cwnd + 1;
transmit
a new packet;
When
a new ACK arrives, do:/* the ACk
for the retransmission */
cwnd
= ssthresh;/* this is congestion
avoidance */
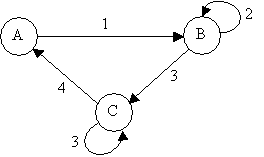
Figure 2. Fast Retransmit Algorithm and State Diagram
|
State
|
Meaning
|
Effective
transmission rate
|
| A |
Normal state | Normal, as specified by advertised window size and the last ACK received. |
| B |
Lost segment has been retransmitted, wait for new ACK. | One segment for each duplicate ACK received. |
| C |
All segments that were buffered at the receiver were acknowledged. | Starts by 1/2 the normal rate (congestion avoidance) and increments linearly with each new ACK received. |
Table
3. States during Fast Retransmit.
|
Event
|
Meaning
|
Description
|
| 1 |
A third duplicate ACK is received | A segment was probably lost, we have to retransmit it. |
| 2 |
A fourth (or more) duplicate ACK is received | One segment has left the network; we can transmit a new segment. |
| 3 |
A new ACK is received. | Retransmitted segment has arrived at the destination and all out of order segments buffered at the receiver (including the retransmitted segment) are acknowledged. |
| 4 |
snd_cwnd has reached snd_wnd | Use advertised window snd_wnd instead of congestion window snd_cwnd. |
Table
4. Events during Fast Retransmit.
iTCP Model Architecture
Before presenting the iTCP mode, we need to define the set of events that we are interested in. Table 5 below summarizes the set of events that can be reported to the application. When the application subscribes for an iTCP service, it must specify which one of those events it wants to receive a notification when it happens.|
Event
Number. |
Meaning |
Occurs in
|
|
|
Slow Start
|
Fast Retransmit
|
||
| 1 | Retransmission timer timed out |
|
|
| 2 | cwnd has reached the slow start threshold ssthresh |
|
|
| 3 | cwnd has reached the advertised window size snd_wnd |
|
|
| 4 | A third duplicate ACK is received |
|
|
| 5 | A new ACK is received |
|
|
Table 5. The set of iTCP events.
The application starts by subscribing to certain iTCP services, see table 7 below for the list of available services. Then, it makes a socket connection and start using the TCP connection as usual. A new entity agent in the TCP kernel will keep monitoring the occurrence of any of events shown above. When any event occurs, the agent will write that down in a special data structure in the kernel space and send a signal to a special Handler. The Handler will check to see if the application has registered for this event. If the answer is yes, it will read the event’s data by invoking a signal handler and return it back to the application. Event’s data will include the event type, and effective transmission rate. Figure 3 below shows the proposed architecture for our iTCP model.
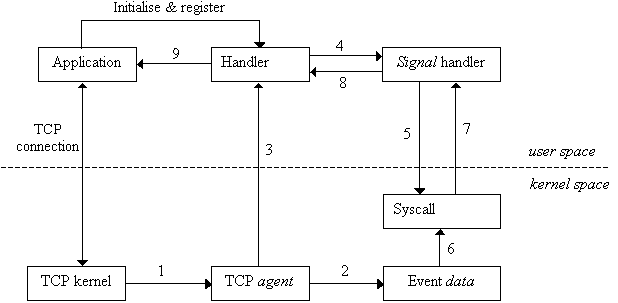
Figure
3. iTCP model architecture.
Assume the application registered with the Handler to receive information
about the event (evt). Table 6 below describes the sequence of operations
that will take place in the iTCP model when event (evt) occurs. The sequence
of these operations corresponds to the numbers shown in figure 3 above.
|
Seq.
|
Description
|
| 1 | Event (evt) has occurred during the normal TCP kernel work. |
| 2 | TCP agent writes event’s data in a data structure Event data. |
| 3 | TCP agent sends a wake-up signal to the Handler. |
| 4 | The Handler invokes a Signal handler. |
| 5 | The Signal handler makes a system call syscall. |
| 6 | Syscall reads the data from the Event data structure. |
| 7 | Syscall returns the data to the Signal handler. |
| 8 | The Signal handler returns the data to the Handler. |
| 9 | The Handler returns the data to the application. |
Table 6. A sequence of operations that takes
place when event (evt) occurs (see figure 3 above).
The model defines a clear interface between the application and the
services provided by the iTCP model. The application uses this interface
to subscribe to a certain iTCP service and to specify the type and quality
of this service. The interface is implemented as a well-defined set of
function calls that the application can make to communicate with iTCP.
Table 7 below presents the function calls and their meanings:
|
Function call
Made by application |
Meaning |
| GetEventSet(evtSet) | Asks the Handler to provide the set of TCP events evtSet that can be reported to the application. |
| GetEventData(evt, evtData) | Asks the Handler to provide information about the event (evt) in evtData. |
| GetSocketData(Soc) | Asks the Handler to provide information about the socket connection sock. |
| RegisterEvent(evt) |
Register with the Handler to receive an interrupt when event (evt) occurs. |
Table 7. The function calls of the application
interface to the iTCP
Other Approaches to Improve TCP Performance
Rate-based pacing TCP (RBP TCP) – [1]
The basic idea of the rate-based pacing mechanism presented in [1] is to reduce the burstiness of TCP data transfers. By spreading out in time the packet transmissions on a given connection, RBP TCP hopes to scatter across several TCP connections the packet losses (if any) that occur during network congestion. In other words, it reduces the possibility of multiple packet losses in the same window. Although TCP recovers easily from most single packet losses, recovering from multiple packet losses often requires a retransmission timeout. Reducing or avoiding multiple packet losses can significantly improve TCP performance.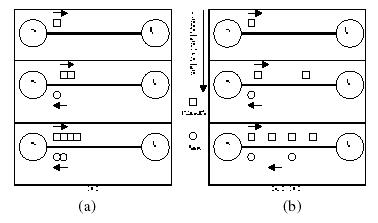
Figure 4. Conceptual illustration of TCP sliding
window flow control and slow-start: (a) Reno TCP; (b) RBP TCP (From [1]).
Figure 4 illustrates the intuitive idea behind RBP TCP. Normal TCP and
RBP TCP each start by sending one segment. Once the server S receives the
ACK from the client C, the server can send two packets. TCP typically sends
two back-to-back packets, while RBP inserts a time delay between these
packets.Rather than sending
back-to-back packets in one window, RBP induces a time delay between
packets. This modification requires changes only at the TCP sender.
The key issue in RBP flow control is the value of the sending rate. This
sending rate is dynamically determined and updated based on RT'T estimation
and the current congestion window size (cwnd).
Using this algorithm, the server is able to send a full window
of packets in slightly less than one estimated round trip time. As the
last packet of a window is being sent, the ACK for the first packet of
this window should be arriving shortly. In contrast, current TCP sends
a full window of packets as rapidly as possible, and then waits for the
ACK for almost one round trip time.
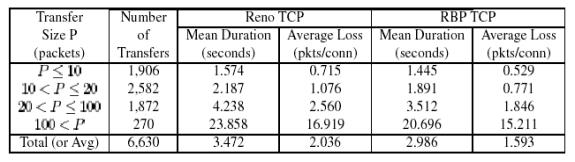
Table 8 classifies the transfer latency and packet loss results based
on the number of packets in each connection. Four arbitrary categories
are identified: Small, Medium, Large, and Very Large. The transfer latency
advantage of RBP TCP is quite consistent across transfer sizes. The performance
advantage for RBP TCP (in terms of average transfer latency) in the four
categories is 8.2%, 13.5%, 17.1%, and 13.3%, respectively.
Adaptive TCP – [2]
Congestion control in the current TCP is closely coupled with reliability. The Authors of [2] suggests that there is a clear need to decouple congestion control from the reliability mechanisms. In particular, the two questions ‘how many packets can be transmitted next?’ and ‘which packet needs to be transmitted next?’ are independent. In TCP, acknowledgements are used as the mechanism to answer both these questions. End-to-end congestion control for Adaptive TCP is based on feedback from the receiver about the fraction of received packets rather than the sequence number of the last received acknowledgement. This effectively decouples congestion control from reliability.Adaptive TCP uses two mechanisms to perform end-to-end adaptation: (a) it uses a robust window-based protocol similar to TCP which adjusts the transmission window based on the fraction of packets received, and (b) it enables applications to provide hints to the network switches about which packets in a flow of multi-priority interleaved streams are high priority.The Adaptive TCP supports multimedia flows by allowing applications
to interleave both reliable and unreliable data into a single sequenced
congestion-controlled stream. In addition, applications can tag data with
a priority level, making it possible for intermediate network nodes
to discard low-priority packets in favour of high-priority packets during
high congestion peaks. The authors of [2] says that flow control in
Adaptive TCP guarantees that the sender will not swamp the receiver with
more data than the receiver buffer can handle. The receiver's advertised
window size for Adaptive TCP takes into account both low and high priority
packets since both occupy space in the receiver's buffer.
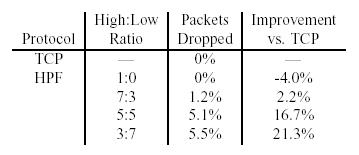
Table
9. The performance of Adaptive TCP (HPF) vs. TCP at various
priority ratios and bursty UDP traffic. (From [2]).
A test was conducted to demonstrate the benefits of mixed reliable and
unreliable streams on overall throughput. The test consisted of a stream
of 5000 packets (1404 payload bytes) using various ratios of high priority
(reliable) to low priority (unreliable) packets. During the transmission,
congestion in the form of multiple bursts of 5000 UDP packets (again 1404
bytes of payload) at 3-second intervals was injected in the network. The
length of time required to complete the transmission of the non-congestion
packet stream was then recorded over multiple runs. Table 9 shows the results.
Note that the 20% reduction in the overall transmission time of the non-congestion
packets comes at the expense of just a 5% loss in low priority packets
(high priority packets are retransmitted), which we believe is well justified.
Comparison
In this section we try to make a comparison between the three approaches presented above. Table 10 below shows the level of improvement in performance that can be made when any one of the three approaches is applied to serve different types of applications. Three levels are shown in the table: (Good) means good improvement, (Poor) means poor improvement, and (No) means no improvement. We selected those levels according to the nature of the proposed approach and its target application type. For example, iTCP might make good improvement for bulk data transfers like video, and when limited bandwidth is available like wireless network. RBP TCP makes good improvement for short-lived Web-like transfers and no improvement for bulk transfers. HPF makes good improvement for Audio/Video and IP-Telephony since they involve multiple streams that can be prioritized.|
|
Interactive TCP(iTCP)
|
Rate-Based TCP(RBP
TCP)
|
Adaptive TCP(HPF)
|
| Audio/Video |
Good |
No |
Good |
| HTML/Text |
Poor |
Good |
No |
| IP-Telephony |
Poor |
Poor |
Good |
| Wireless
Network |
Good |
No |
Poor |
Table 10. Level of
performance improvement for the three approaches with different types of
applications.
Summary
In this survey we presented an interactive mechanism for TCP. In this mechanism the application cooperates with the TCP to reduce traffic during network congestion. We believe that this is a simple and efficient way to achieve higher throughput and lower packet loss especially for bulk data transfers. Yet, we have to do extensive experimenting to calculate the amount of overhead involved in iTCP versus the potential improvements in congestion control to verify the effectiveness of this approach.We also presented two other approaches suggested in the literature to
deal with TCP performance issues. First, we presented a rate-based pacing
mechanism for TCP (RBP TCP) described in [1]. Their simulation experiments
showed that RBP TCP reduces packet loss and average transfer delay for
Web-like workloads, but they did not study the potential impact of RBP
TCP on the entire network. Such studies should consider more complicated
network topologies, heterogeneous RTTs, delayed ACKs, and inter-operability
between RBP TCP and other TCP versions.Second,
we presented an Adaptive TCP approach described in [2] to support heterogeneous
packet flows. They proposed a transport protocol (called
HPF) that supports multiple interleaved data sub-streams with
different priority levels. Also, they showed that we can provide congestion
control for unreliable streams as well as reliable streams by decoupling
the congestion control and reliability mechanisms that are integrated
in TCP. They experimented with a small testbed and showed that this approach
can provide effective support for heterogeneous packet flows, but
they need to validate their results over a larger scale laboratory testbed
and over the Internet.
In addition to the approaches presented in this survey, there are many
other approaches suggested by researchers to deal with TCP performance
issues. Each one of them came up with a modified version of the TCP’s congestion
control mechanism targeted towards different kinds of congestion problems
or different types of applications. We found that researchers have different
points of view concerning the current TCP congestion control mechanism,
while some of them thinks that it has a very poor performance like [4],
others – like [3] - suggests that TCP should not be redesigned. They said
that practical experience suggests that TCP’s congestion control algorithm
is better than many of the proposed alternatives.
We think that no single approach can solve all performance issues; but
for any approach to be effective it should be simple (i.e. it should include
minimum overhead), and any modification made to the TCP should be minimum.
Also, to prove the effectiveness of any proposed approach, it should go
through aggressive testing on a large-scale testbed or over the Internet
for a long time.
References
[2]
Dane Dwyer, Sungwon Ha, Jia-Ru Li, Vaduvur Bharghavan, “An
Adaptive Transport Protocol for Multimedia Communication“,
IEEE International Conference on Multimedia Computing and Systems 1998
(ICMCS’98), Pages 23-32.
[3]
Richard Karp, Elias Koutsoupias, “Optimization
Problems in Congestion Control”, 41st
Annual Symposium on Foundations of Computer Science 2000 (FOCS’00), Pages
66 – 74.
[4]
Sherlia Shi, Marcel Waldvogel, “A
Rate-based End-to-end Multicast Congestion Control Protocol”, Fifth
IEEE Symposium on Computers and Communications 2000 (ISCC’00), Pages 678
– 686
[5]
Haining Wang, Hongjie
Xin, Douglas
Reeves, Kang
Shin, “A
Simple Refinement of Slow-start of TCP Congestion Control”, Fifth
IEEE Symposium on Computers and Communications 2000 (ISCC’00), Pages 98
– 105.
[6]
Reza Rejaie, Mark Handley, Deborah Estrin, “Architectural
Considerations for Playback of Quality Adaptive Video over the Internet”,
Proceedings
of the IEEE International Conference on Networks 2000 (ICON'00), Pages
204 – 209.
[7]
D. Sisalem, H. Schulzrinne, “Congestion
Control in TCP: Performance of Binary Congestion Notification Enhanced
TCP Compared to Reno and Tahoe TCP”, Proceedings
of the 1996 International Conference on Network Protocols (ICNP'96), Pages
268 – 274.
[8]
Dorgham Sisalem, Adam Wolisz, “Towards
TCP-Friendly Adaptive Multimedia Applications Based on RTP”, Proceedings
of the The Fourth IEEE Symposium on Computers and Communications 1999 (ISCC’99),
Pages 166 – 172.
[9]
Prashant Pradhan, Tzi-cker Chiueh, Anindya Neogi, “Aggregate
TCP Congestion Control Using Multiple Network Probing”, Proceedings
of the The 20th International Conference on Distributed Computing Systems
2000 (ICDCS’00),
Pages 30 – 37.
[10]
Bhaskar Maruthi, Arun Somani, Murat Azizoglu, “Interference
Robust TCP”, Twenty-Ninth
Annual International Symposium on Fault-Tolerant Computing 1999 (FTSC’99),
Pages 102 – 109.
[11]
W. Richard Stevens, “TCP/IP Illustrated, Volume 1, The Protocols”, Addison-Wesley
Longman, Inc., 1993.
[12]
W. Richard Stevens, Gary R. Wright, “TCP/IP Illustrated, Volume 2, The
Implementation”, Addison-Wesley
Longman, Inc., 1995.
Related Links
IEEE
International Conference on Multimedia Computing and Systems 1998
Fifth
IEEE Symposium on Computers and Communications 2000
Proceedings
of the The Fourth IEEE Symposium on Computers and Communications 1999