
ThongChanchaem
email: tchancha@kent.edu,
Prepared for Prof. Javed I. Khan
Department of Computer Science,
Date: May 2003
Abstract: This survey presents information about an existing
work related to web content transcoding. In this paper presents an
overview of different techniques that are available to transcode web contents. There are some works that
are commercial products and some works that are still in progress.
Keywords: Transcoding, Annotation
Other
Survey's on Internetwork-based Applications
Back to Javed
I. Khan's Home Page
What is transcoding? and
Why we need it?
Classification of existing transcoding
Examples of the existing transcoding system
Annotation-based Web content transcoding
Fuzzy-Based Transcoding System
Open Problem and Research
direction
Research Papers for More Information on
This Topic
Introduction
What is transcoding? and Why we need it?
As the incredible growth of mobile communications, the variety of the client devices such as personal digital assistants (PDA), smart phone, hand held PC and WebTV are gaining access to the Internet.[1,7] The Japanese mobile communications company NTT DoCoMo estimates that by 2010, approximate by two thirds of their mobile connections will be from such sources (see table 1). [10]
|
Connected via mobile |
Number (Millions) |
|
Humans Cars Bicycles Portable PCs Vending machines, boats, motorcycles, etc. |
120 100 60 50 30 |
|
Total |
360 |
Table 1. NTT DoCoMo’s
Customer Predictions for 2010
(Source: The Economist, October 9,1999) [10]
Most
existing HTML documents are created to be displayed on desktop
computers [1,9] and web site designers love to provide complex, detailed
content, rich with multimedia experiences.[4] Therefore, the mismatched
problem between the client devices decoding capabilities, such as
memory, color and display size, and HTML documents encoding requirements
is occurred.[2,3,4,7,9]
To cope
with the mismatch problem, the different version of the same original
HTML document depending on each device capability has been provided [1,4]. The process that provided a content
adaptation called transcoding.[9] Moreover, transcoding also includes a
new advance function such as user preference and session content.
Transcoding not only provides a
content adaptation to match client devices, but also integrates the transcoded result to meet the requirement
depending on user preferences such as summarized document and language
translator [5].
This paper presents an overview of
the existing transcoding heuristic and an example of the transcoding
system that available.
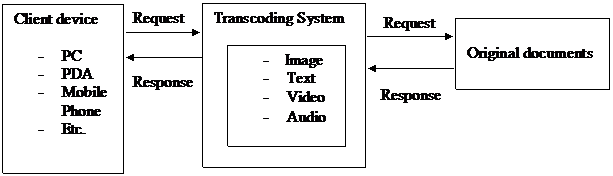
Figure 1
From
figure 1, the different kinds of client devices request the web content.
In this case, the transcoding system is running on proxy server. The
proxy server requests the information from the origin server after the
proxy server receives the original document. The transcoding system
selects the suitable transcoding heuristic by considering the device
profile, network bandwidth, user preference and so on. After the
transcoding system adapts the content such as image, text, video and
audio, it sends back the adapted content that match the need and device
capability of the user. Finally, the client device can display the
content properly.
Classification
of existing transcoding
The existing transcoding heuristic can be classified into two
categories:
q The semantic transcoding [5]. This heuristic use an annotation to provide the guideline information for the transcoding system .
q The syntactic transcoding. This heuristic use some function to
analyze the information from the syntax.
In paper
[1], they classified the existing transcoding techniques into two
categories: client-side approaches and server-side approach.
q The client-side approaches : client device
received the whole content from the HTTP server and convert the content
format locally. The disadvantage is only limited number of transcoding
heuristics can be used therefore the quality of transcoded
pages is poor. Pixo and Pad ++ are the
example of this technique.
q The server-side approaches : The server-side techniques do not have limitation of client-side techniques and the server-side techniques can do more sophisticated transcoding heuristics than client-side techniques. Server side-techniques can classified into three groups manual, semi-automatic and fully – automatic techniques.
§ The manual approach , device – specific authoring approach, uses the characteristics of each device in the re-authoring process, so it can produce high quality transcoded page. The disadvantage of these technique is very inconvenient when the device characteristics change or the web page update the corresponding pages must be re-authored.
§ The semi-automatic approach, page filtering, uses the particular keywords or regular expression to annotate web documents. The annotated web page are transcoded base on the annotations. The disadvantage of these technique is good only when user access the page that do not change frequently.
§ The fully automatic approach, automatic re-authoring, re-authors web page in a fully transparent fashion to the web authors. The disadvantage is the poor quality of transcoded pages. The paper [1] suggests the reason behind the poor quality is that existing heuristics ignored the partial semantic information that can be extracted from the syntactic analysis.
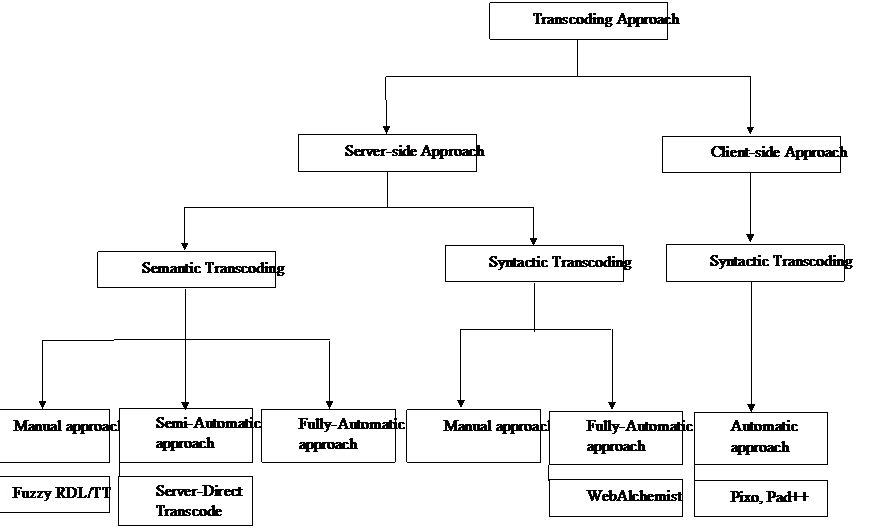
Figure 2
From
figure 2, we combine the classification and example of transcoding
together. This chart shows the relationship between the transcoding
heuristic and transcoding technique.
Examples
of the existing transcoding system
The
first example is WebAlchemist system
[1].These system is a part of a HTTP proxy server, and it consists of
four main module. The first one is HTML Tokenizer
. This module classifies the content of HTML web page into HTML tags and
non tags. The second one is Grammar corrector. This module corrects any
HTML syntactic errors in the HTML page. The next one is Internal
representation generator. This module generates a tree-based internal
data representation that is a data structure for transcoding. And the
last one is transcoding manager. This module controls decides which
heuristic is applied for a given HTML page. After the transcoding
procedure is completed, it converted back to the HTML source format.
The WebAlchemist system consists of three improve
transcoding Heuristics.
The first one is Selective Elision
Transform. The Selective Elision Transform give the elision level on
each cell.The cell that have lower elision
level is likely to elide. The second one is Restricted First Sentence
Elision Transform. This heuristic makes the first sentence of
corresponding paragraph into the hyperlink and the whole text block is
linked to the first sentence. If the text block is with in a table
structure or a text block includes a table structure, the selective
elision transform is applied. The last one is Improved Outlining
Transform. The original outlining transform applied only between the
section header and following text block ,but the improved outlining
transform support the relationship between the “UL” and “LI” tag.
The WebAlchemist is base on five transcoding
heuristics.[1] They test these system by
choosing the different order of transcoding heuristics. The best
heuristic order that they found so far are :
1. The image reduction and elision transforms.
2. The improved outlining transform
3. The restricted first sentence elision
transform
4. The indexed segmentation transform
5. The selective elision.
This
group believe that that more semantic information can be extracted by
more complete syntactic analysis. Therefore the main future work of
these group is to develop more heuristics that can extract semantic
information from the syntactic analysis.
Annotation-
Based Web Content Transcoding
The
second example is Annotation- based Web
content transcoding. This paper [9] use the idea of applying an
annotation to a document depends on the transcoding policy. They use
annotations to provide hints that enable a
transcoding engine to make better decision on the content adaptation.
The advantage of and annotation-based transcoding approach is the
possibility of content adaptation based on semantics. This cannot be
archived with existing commercial products, which adapt contents on the
basis of web document syntax [9]. They focus on page fragmentation for
small screen devices and develop the annotation-based transcoding system
on top of a programmable proxy server. They used three types of
annotation : alternative, splitting hints and selection criteria to
create an annotation file. The transcoding proxy will used this file as
a hint to adapt the content. This group give a note that page
fragmentation beads on semantic annotation will be more appropriate than
page transformation done by solely syntactic information [9].
Fuzzy-Based
Transcoding System
The
third example is a Fuzzy-Based Transcoding System [2]. This system used
user and hardware profile, fuzzy rule definitions, set of transcoding
specifications, and an XML-based document as input and generates a
different XML based document as output. They used user and hardware
profile to provide the information of content splitting and visual
abilities. In the process of transcoding, the Fuzzy-RDL/TT system is
composed of three parts. The first one is fuzzy set definitions. This
process will define a set of values that are given from the different
device categories. The next one is fuzzy rule definition. This process
will use the decision table to create a rule. The last one is
transcoding definition. This process used the previous definition and
rule to create the transcoding function. After that, they use the transcode rule to delete node, insert node,
replace node, assign a new name to replace with link. The transcoding
functions are specified by a Java oriented language with operate on the
DOM tree representation of and XML-base document [2].Currently, this
system only have transcoding definition for complete HTML to C-HTML and
to WML for PDA. They have a few rules for small phones and smart phone.
They also investigate a combined transcoding to C-HTML and VoiceML with speech synthesis [2].
The
fourth one is Server-direct transcoding [4]. In this approach, the
original server provide explicit duidance to
the transcoding system such as client or proxy. They believe that the
traditional transcoding breaks the end-to-end model of the web, because
the proxy does not know the sematics of the
content. Server-directed transcoding preserves end-to-end semantics
while supporting aggressive content transfomation
[5]. They provide the transcoding guidance by defining a new HTTP header
and using the transcoding applet as a
guidance.
IBM InfoPyramid
The
last one is IBM InfoPyramid. The system
retrieves and analyzes the
Internet content and convert them into the InfoPyramid
format. A policy engine gathers the capabilities of the client, the
network conditions, and the transcoding preferences of the user and
publisher [7,8] This information is used to
define the transcoding options for the client. They used this idea in
their product named as IBM WebSphere
[11,12]. The IBM WebSphere Transcoding
Publisher is network software that modifies content presented to user
based on the information associated with the request, such as device
constraints, network constraints, user preferences and organizational
policies. The IBM WebSphere Transcoding
Publisher product provides a framework for proxy transcoding plug-ins,
using Java applets and library of built-in transformations [4].
From
the examples, we can see that the current transcoding system is mostly
executed on proxy server and some transcoding system use origin server
to provide a hints to adapt content at
proxy server. Some said that server can provide the complete information
and intention for producing a good quality of the transcoding
by using semantic transcoding. Another said that if they can get enough
information form the syntax analysis, they can generated the good
quality of the transcoding output. In the
server transcoding approach, There are some trade-off. One of them is an
extra connection for downloading the hints from original server such as
annotation file and transcoding applet. While the proxy transcoding
approach with syntax analysis is lack of important information from
origin server.
Open
Problem and Research direction
Research
Papers for More Information on This Topic
[1] Y. Whang, C. Jung, J. Kim and
S. Chung "WebAlchemist: A Web Transcoding
System for
[2] R. Schaefer, A Dangberg, W. Mueller. “Fuzzy Rules for the
Transcoding of HTML Files.” HICSS 35,
[3] A. Singh, A. Trivedi and K. Ramamritham. “PTC :
Proxies that Transcode and Cache in
Heterogeneous Web Client Environments”, WISE 2002,
[4] J.C. Mogul, "Server-Directed Transcoding", Computer Communications 24(2):, pp.155-162, Feb. 2001.
[5] B. Knutsson, H. Lu and J.
Mogul, "Architecture and Pragmatics of Server-Directed Transcoding",
Proc. 7th International Workshop on Web Content Caching and
Distribution,
[6] K. Nagao,”Semantic Transcoding: Making the World Wide Web More Understandable and Usable with External Annotations”, In Proc. of International Conference on Advanced in Infrastructure for Electronic Business, Science, and Education on the Internet ,2000.
[7] J. Smith and R. Mohan and C. Li,” Transcoding Internet content for heterogeneous client devices”, Proc. IEEE Int. Conf on Circuits and Syst.(ISCAS), May 1998.
[8] R. Mohan, J. Smith, C.-S. Li, "Adapting Multimedia Internet Content For Universal Access", IEEE Transactions on Multimedia, pp. 104-114, March 1999.
[9] Hori M., Kondoh G., Ono K., Hirose S. and Singhal S. “Annotation-based web content transcoding”. In Proc. of Ninth Internetional WWW Conference, pp. 197–211, 2000.
[10] Chris B,”Practical WAP : developing applications for the wireless
web”,
[11] IBM Research.
[12] WebSphere Software
- IBM Research Laboratory
- Compaq Computer Corporation Western Research Laboratory
This survey is based on electronic search in OhioLink’s
The
keywords that used for searching are “transcoding”, “web transcoding”
and “annotation”.